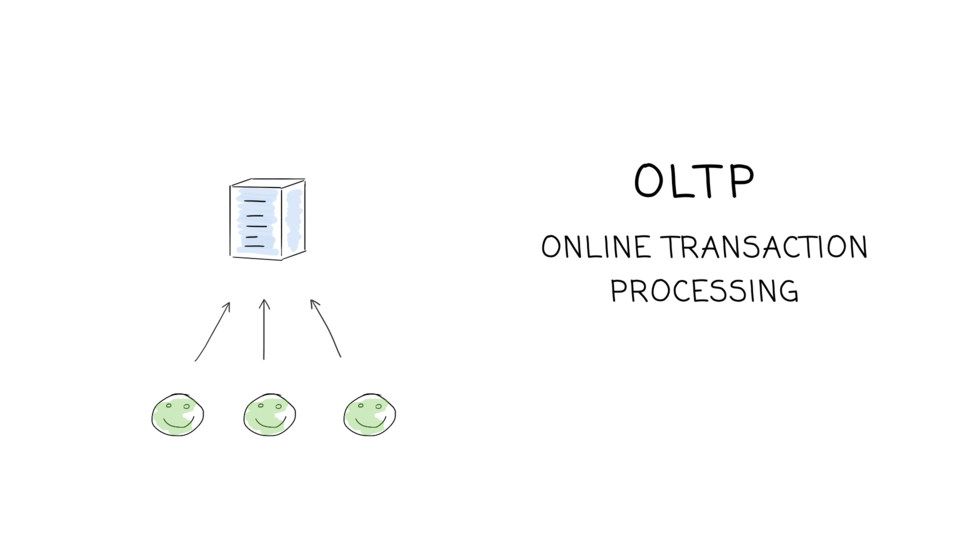
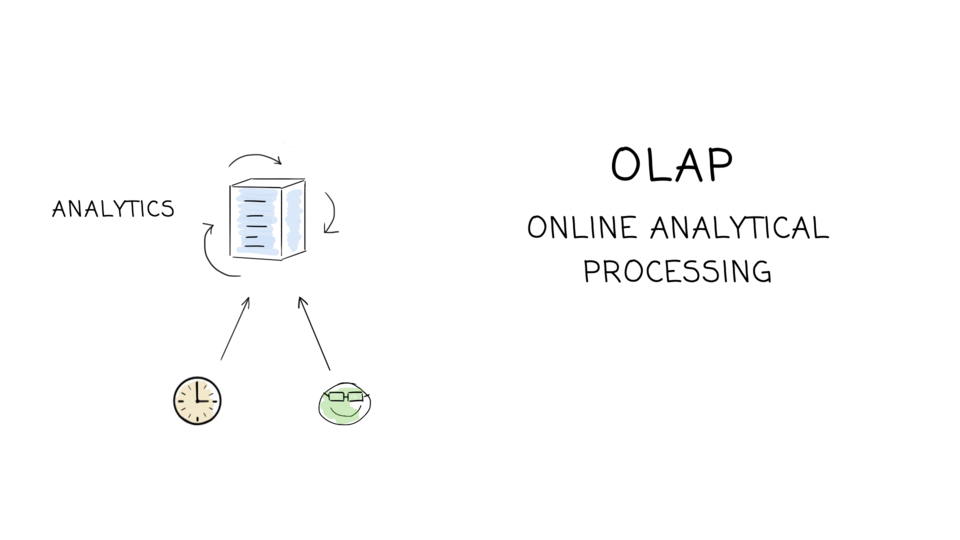
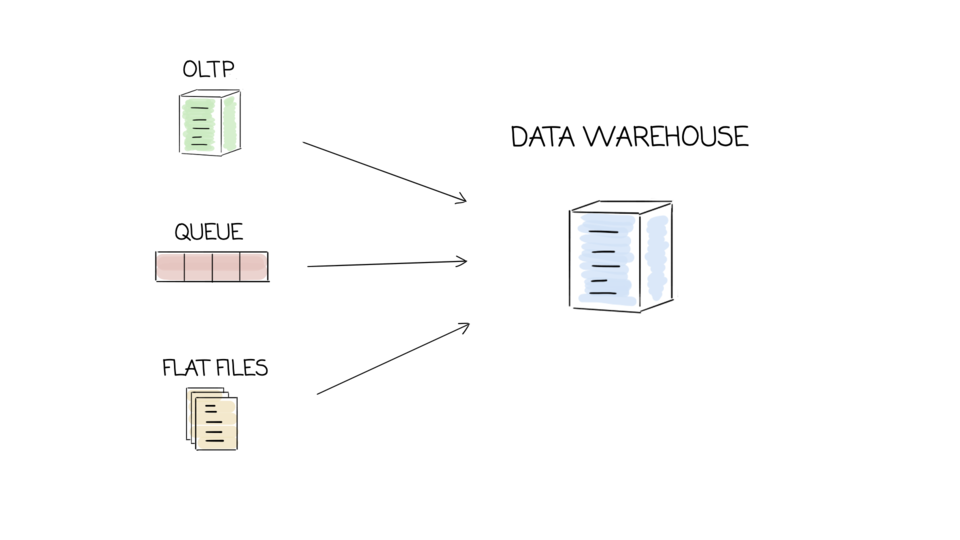
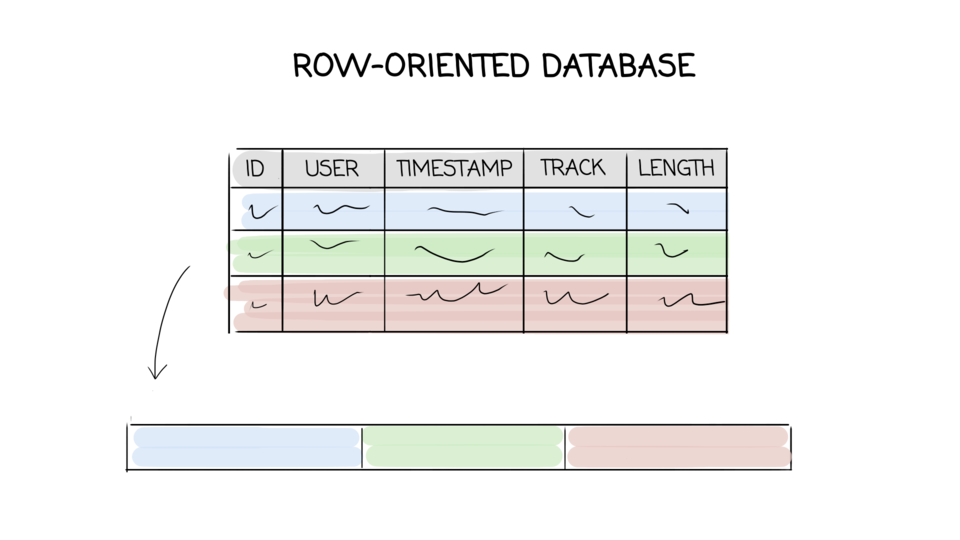
These are the slides I use for my talk “What every software engineer should know about modern databases”, together with sources and additional links.



- modern-sql.com - latest features in SQL

- ACID (Wikipedia)
- M. Kleppmann, Designing Data-Intensive Applications, chapter 7. Transactions

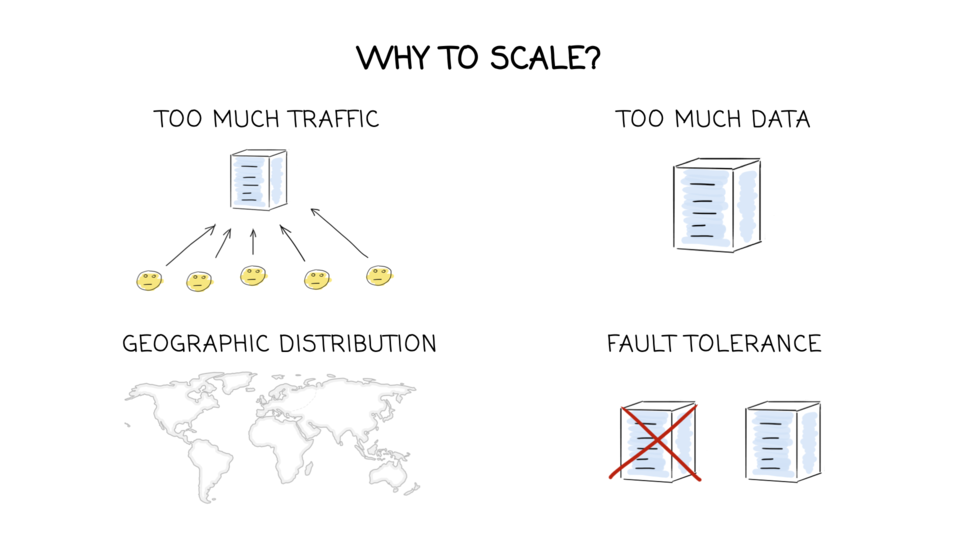
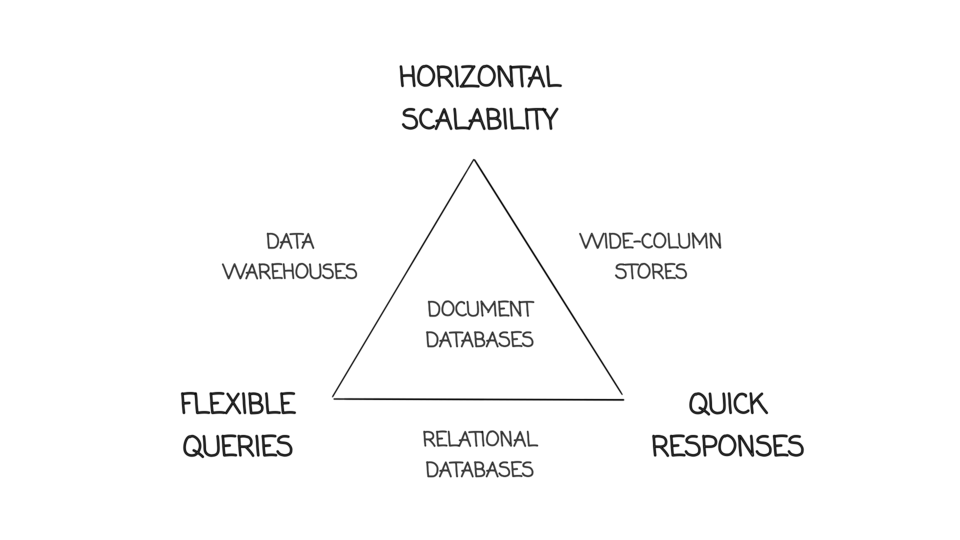
- “There are various reasons why you might want to distribute a database across multiple machines: Scalability (data volume, read load, or write load) (…),
Fault tolerance/high availability, (…), Latency (…)”
M. Kleppmann, Designing Data-Intensive Applications, Part II. Distributed Data
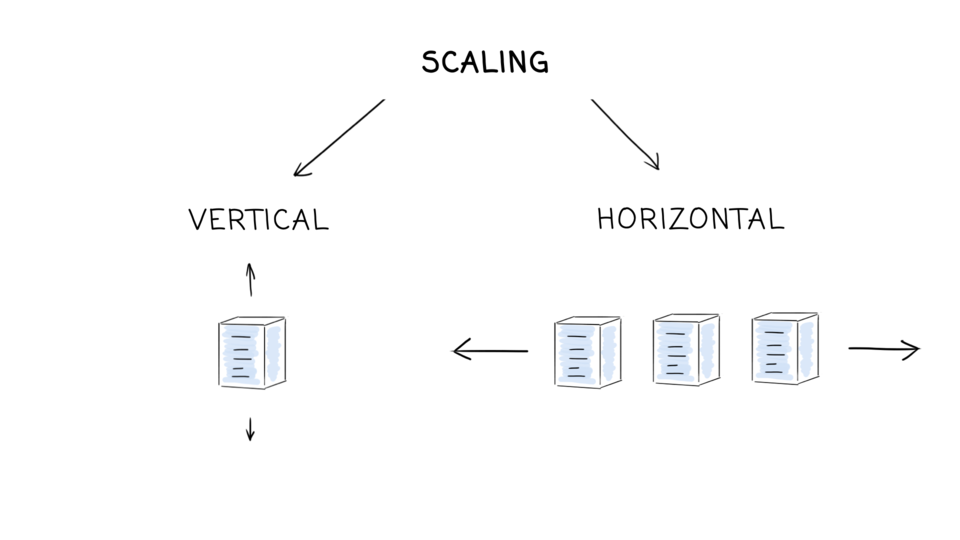
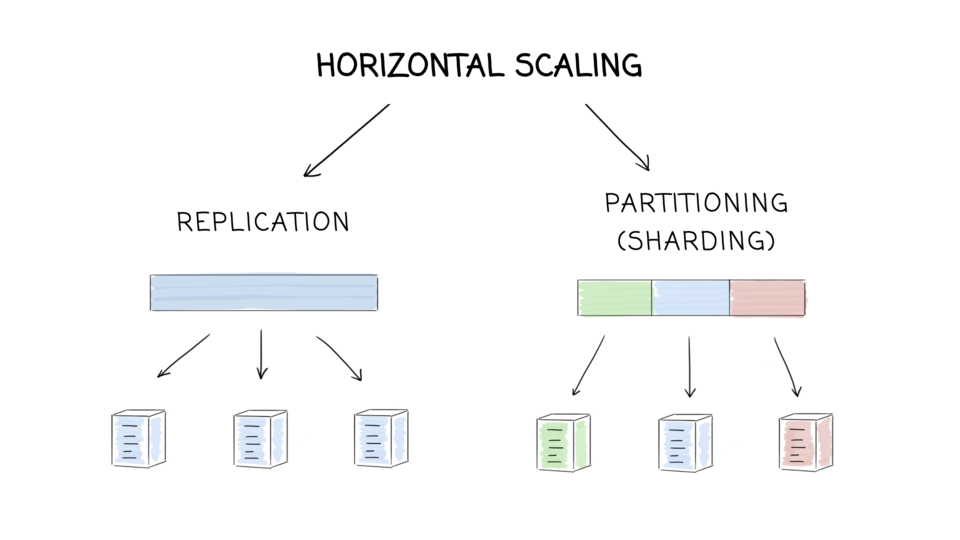
- Replication (wikipedia)
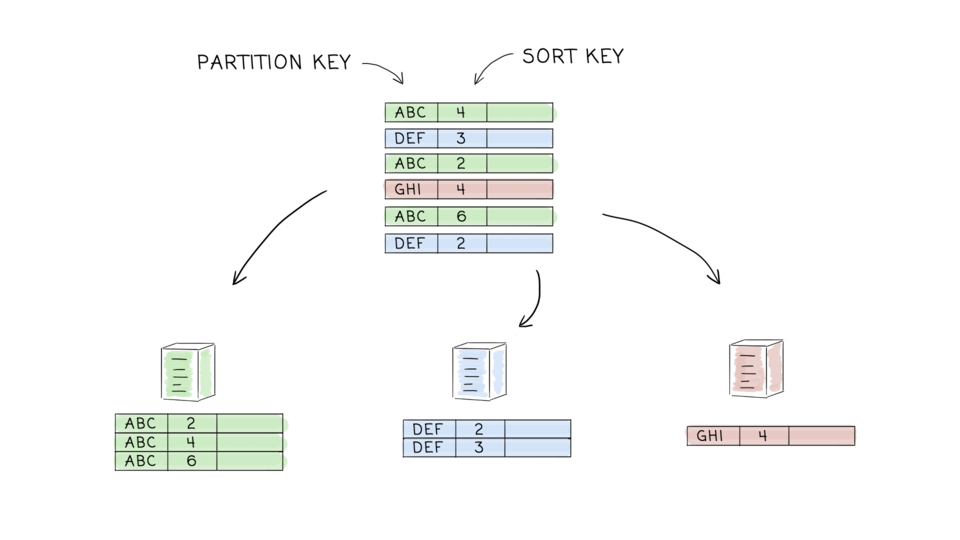
- Partitioning (wikipedia)
- M. Kleppmann, Designing Data-Intensive Applications, chapter 5. Replication
- M. Kleppmann, Designing Data-Intensive Applications, chapter 6. Partitioning
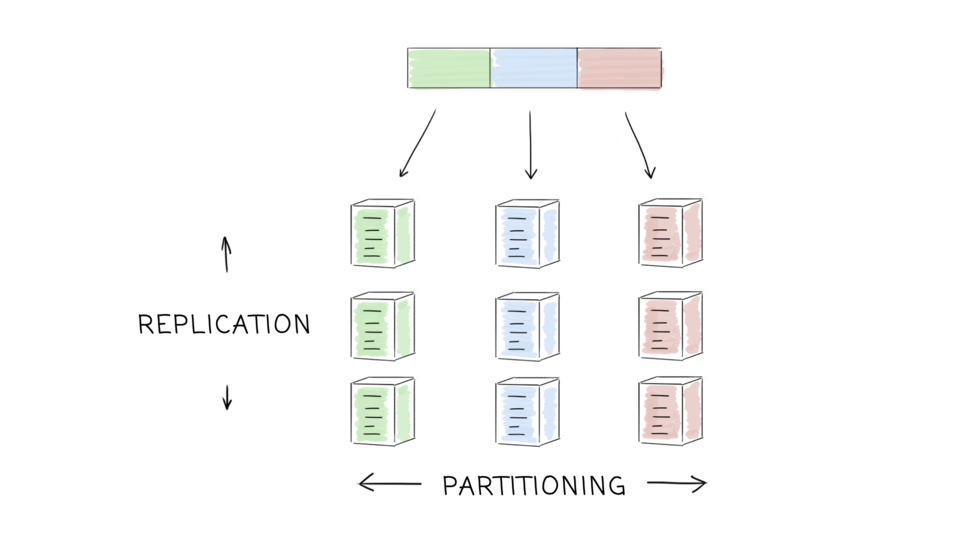
- “Partitioning is usually combined with replication so that copies of each partition are stored on multiple nodes. This means that, even though each record belongs to exactly one partition, it may still be stored on several different nodes for fault tolerance.”
M. Kleppmann, Designing Data-Intensive Applications, chapter 5. Replication
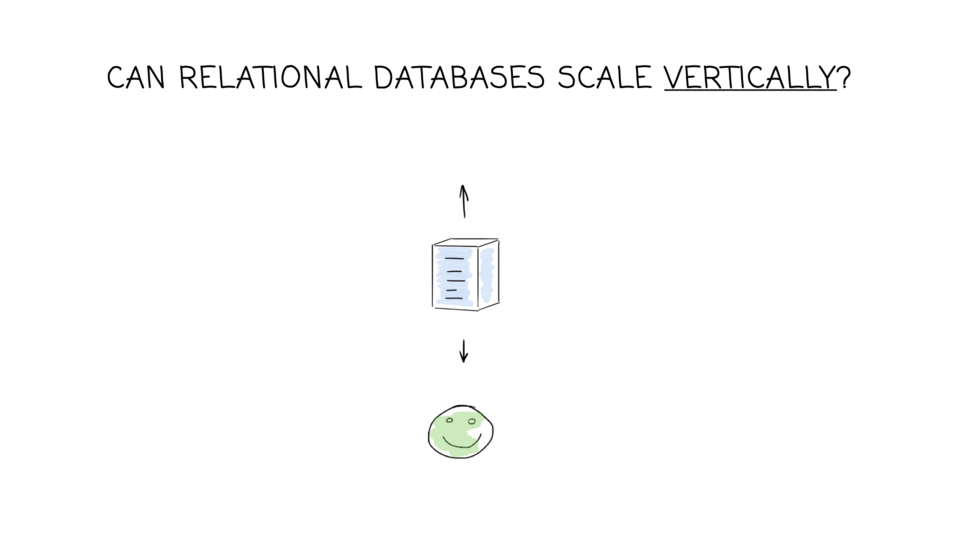
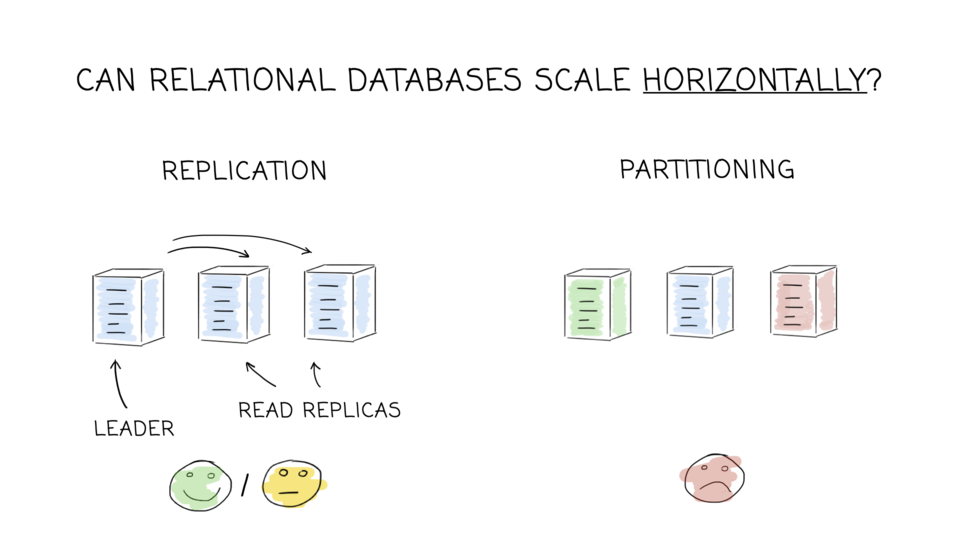
Replication:
- Scaling Your Amazon RDS Instance Vertically and Horizontally
(note that the horizontal part is only about replication) - High Availability, Load Balancing, and Replication in PostgreSQL
Partitioning:
- Sharding in Oracle Database
- Limitation in Oracle Database sharding
- Citus - an extension to PostgreSQL that adds partitioning
- MySQL sharding approaches? (Stack Overflow)

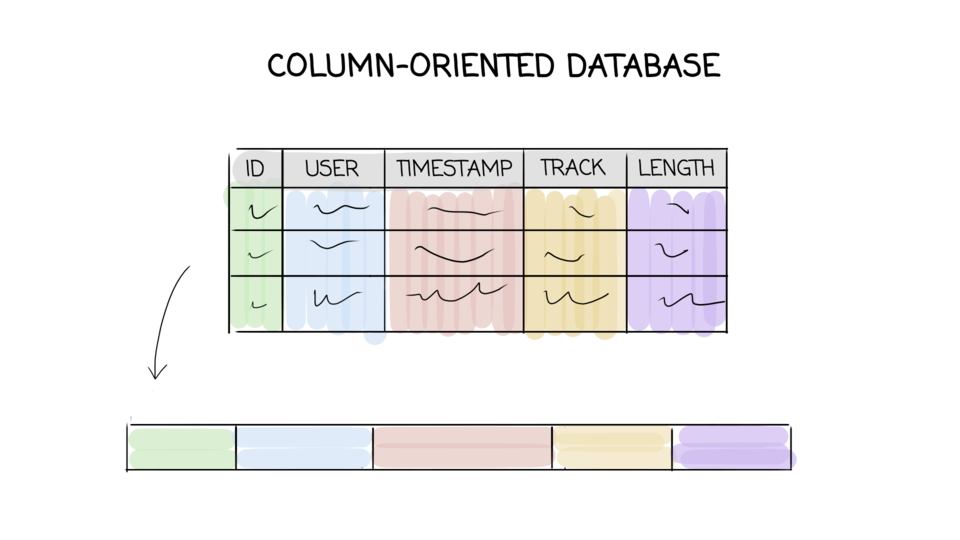
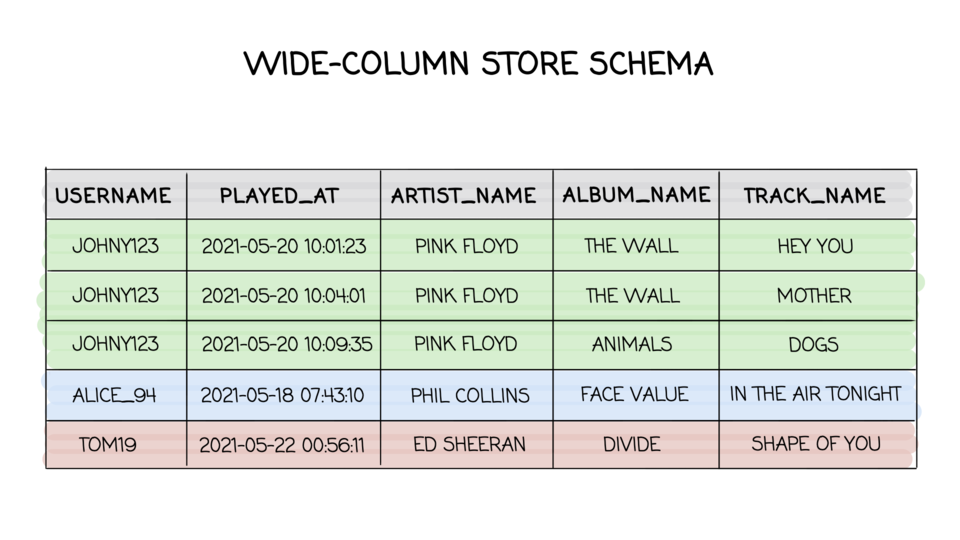
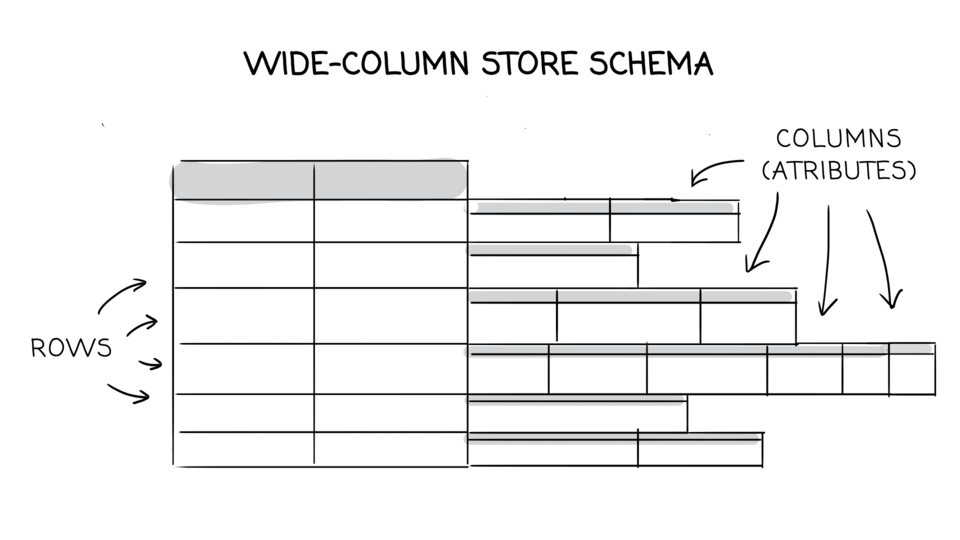
- Wide-column store (Wikipedia)
- “Traditionally production systems store their state in relational databases. For many of the more common usage patterns of state persistence, however, a relational database is a solution that is far from ideal. (…) Although many advances have been made in the recent years, it is still not easy to scale-out databases or use smart partitioning schemes for load balancing.”
2007 Dynamo paper - 2006 Bigtable paper
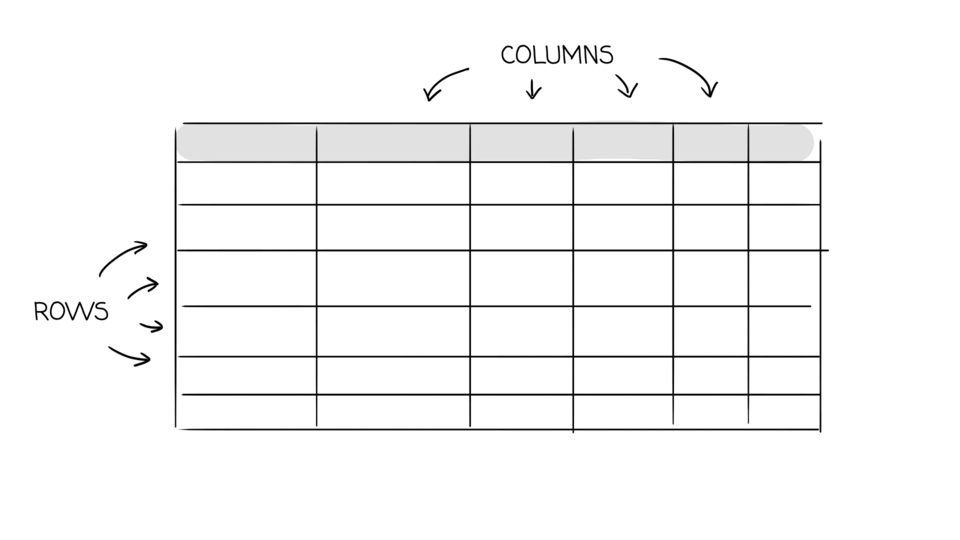
- Apache Cassandra stores data in tables, with each table consisting of rows and columns. CQL (Cassandra Query Language) is used to query the data stored in tables. Apache Cassandra data model is based around and optimized for querying. Cassandra does not support relational data modeling intended for relational databases.
Cassandra documentation - Introduction to Data Modeling - Storage model in Bigtable





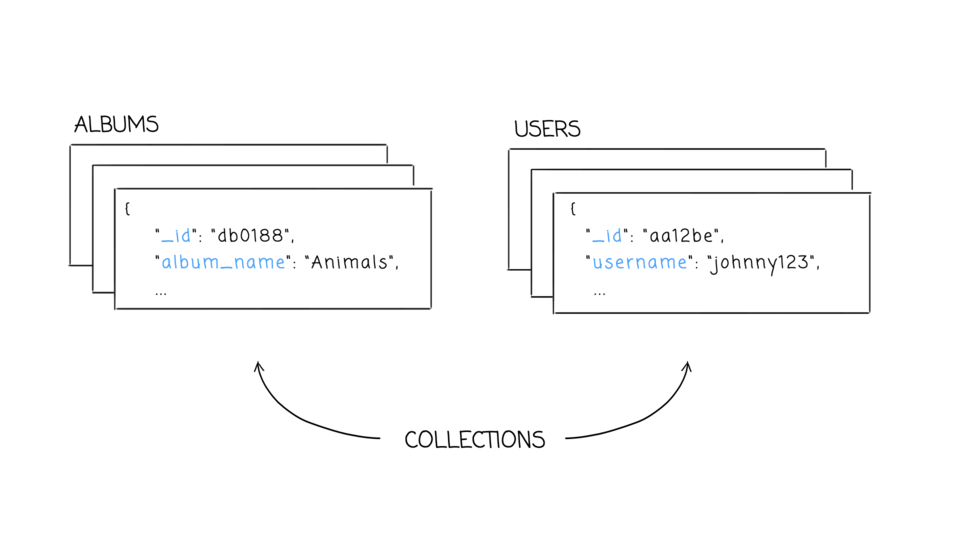
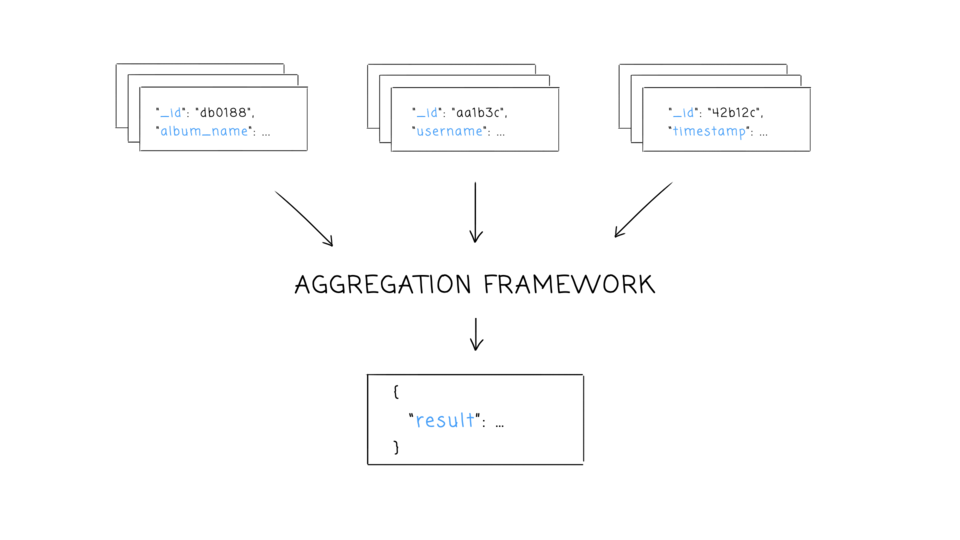
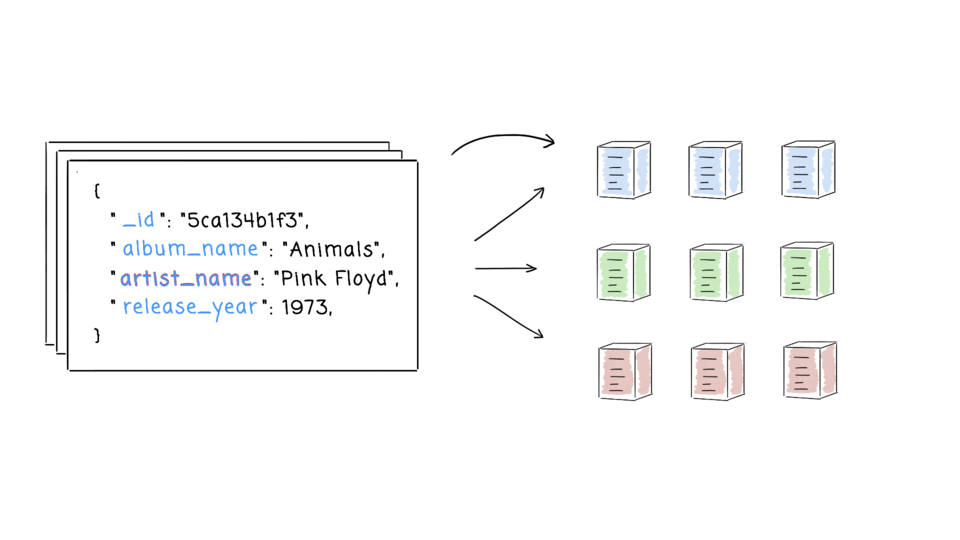


- Mongo hits a sweet spot between the powerful queryability of a relational database and the distributed nature of other databases, like HBase. Project founder Dwight Merriman has said that MongoDB is the database he wishes he’d had at DoubleClick, where as the CTO he had to house large-scale data while still being able to satisfy ad hoc queries.
Luc Perkins, Seven Databases in Seven Weeks - Was MongoDB ever the right choice?
- Everything You Know About MongoDB is Wrong!, Myth 5. Sharding